BedquiltDB Conceptual Overview
This document attempts to describe BedquiltDB at a high level.
BedquiltDB Architecture
BedquiltDB is divided into two components:
- The
bedquiltextension for PostgreSQL - A set of client "driver" libraries
Once the bedquilt extension is installed on a PostgreSQL server, a driver library can be connected to the server and used to read and write JSON data. The driver proivides
an API that feels native to the language it is written in and manages
conversion from language-native data structures to JSON and back again.
The following diagram illustrates how a web application written in python might use
the pybedquilt driver to interface with a database which has bedquilt installed:
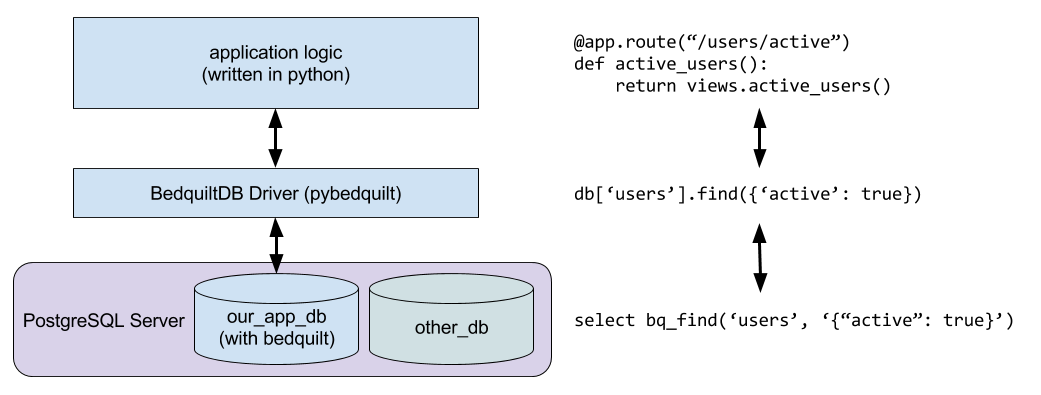
As we can see from the diagram, the drivers find method is really a thin wrapper
around an SQL statement which uses a SQL function called bq_find, which is provided
by the bedquilt extension. All of the functionality of BedquiltDB is
implemented in this way, with all the "smart stuff" implemented inside the database,
behind custom SQL functions.
This approach provides several advantages over simply writing wrapper logic around SQL in a specific language:
- The logic of BedquiltDB is performed inside the database, close to the data
- Driver libraries become very simple to implement and test
For more information on setting up BedquiltDB, see Installation.
Drivers
To use BedquiltDB, the programmer will need to import a BedquiltDB driver for their favourite programming language and use it to connect to the PostgreSQL/BedquiltDB server. Example, with the pybedquilt driver:
import pybdequilt
db = pybedquilt.BedquiltClient('dbname=test')
The db object holds a connection to the server, and provides an api for the collections in the BedquiltDB database.
Collections
In a BedquiltDB database, JSON data is stored in collections. You write data into collections, then read it back out later, like so:
# create a collection called 'users'
db.create_collection('users')
# get a Collection object, referencing the new 'users' collection
users = db['users']
# How many users do you think we have?
print users.count()
Documents
Collections contain documents. A document is essentially a single JSON object.
The BedquiltDB driver handles converting from native data-structures to JSON and back again.
A document can have practically any structure you could want, as long as it's valid JSON,
with one exception: all documents must have an _id field, with a string value.
If a document without an _id field is written to a collection, then a random string will be
generated and set as the _id value. The _id field is used as the unique primary-key in
the collection. If two documents are saved with the same _id, then the second one will over-write the first.
Here we see an example of saving a python dictionary to a BedquiltDB collection as a JSON object:
users.insert({
"_id": "john@example.com",
"name": "John",
"age": 45,
"address": {
"street": "Elm Row",
"city": "Edinburgh"
}
})
We can read that same document out later:
john = users.find_one_by_id("john@example.com")
Or retrieve it as part of a more general query:
edinburgh_users = users.find({"address": {"city": "Edinburgh"}})
Writing Data
There are two operations which write JSON data to a collection: insert and save.
The insert operation takes a JSON document and inserts it into the collection, generating
an _id value if needed. Regardless, the insert operation always returns the _id of the
inserted document:
print pets.insert({"name": "Snuffles", "species": "dog"})
# => "ba40513444b760b7eb2684d8"
print pets.insert({"_id": "some_meaningful_identifier", "name": "Larry", "species": "cat"})
# => "some_meaningful_identifier"
The save operation also takes a JSON document, but it first
checks if the document has an _id field. If it does, and a document with that same _id
exists in the collection, then the old document will be overwritten by the new one.
Otherwise, save behaves the same as insert: if there are no documents in the collection
with the same _id then the document is simply inserted into the collection, and the
_id returned to the caller:
john = users.find_one_by_id('john@example.com')
john['age'] = 46
result = users.save(john)
print result
# => "john@example.com"
Reading Data
There are three operations which read json documents out of collections: find, find_one
andfind_one_by_id. The find operation takes a "query document" and compares it to
the documents in the collection, returning the set of documents which match the query.
A document is considered a match if the query matches some subset of the document.
For example, we could find all active users:
cool_people = db['users'].find({
'active': true
})
or, we could find all active users who are living in Edinburgh:
cool_people = db['users'].find({
'active': true,
'address': {
'city': 'Edinburgh'
}
})
or all active users in Edinburgh who have both "icecream" and "code" in their list of likes:
cool_people = db['users'].find({
'active': true,
'address': {
'city': 'Edinburgh'
},
'likes': ['icecream', 'code']
})
We can also just query for all documents in the collection, by suppling an empty query document:
cool_people = db['users'].find({})
For some BedquiltDB drivers, the result of a find operation will be a Cursor of results,
rather than an Array. Generally the driver should use the languages equivalent of lazy sequences to prepresent query result sets. This is so that the results can be streamed from the PostgreSQL server to the client as needed, rather than being eagerly materialised in memory:
print db['users'].find({...})
# => <pybedquilt.core.BedquiltCursor at 0x101cb8a90>
We can iterate over the cursor, pulling in results as they are needed:
result = db['users'].find({...})
for doc in result:
print doc
Or we can just turn the result into a list:
result = list( db['users'].find({}) )
print type(result)
# => list
The find_one operation also takes a query document, just like find,
but it only returns at most a single result,
or null if there were no matching documents:
print db['users'].find_one({'email': 'user@example.com'})
# => {_id: '...', 'email': '...', ...}
print db['users'].find_one({'this': 'matches': {'nothing'}})
# => None
As if that weren't enough, the find_one_by_id operation takes a string id instead
of a query document, and returns the document with the matching _id field, or null
if there are no documents with that _id.
print db['users'].find_one_by_id('400241')
# => {_id: '400241', ...}
If we have a list of document ids, we can use find_many_by_ids to get them all
in one query, rather than using find_one_by_id multiple times:
print db['orders'].find_many_by_ids(['X2242', 'X5373', 'X1762'])
We can also get a list of the distinct values we may have under a given key, with
the distinct operation.
print db['users'].distinct('address.city')
Advanced Queries
All of the examples so far have queried for documents which match a query document. In other words, the query document should be a sub-set of the matched document. BedquiltDB also supports more advanced query operations. For example, we can test that a certain field does not equal to a given value:
print db['orders'].find({
'address': {
'city': {
'$noteq': 'Glasgow'
}
}
})
Or that a numeric field is greater than a certain value:
print db['articles'].find_one({
'upvotes': {
'$gt': 4
}
})
Of course, we can intermingle these special queries with ordinary matching queries too:
print db['orders'].find({
'processed': True',
'address': {
'city': {
'$noteq': 'Glasgow'
},
'address1': 'Church Street'
}
})
See the BedquiltDB Spec for full documentation on advanced query operations.
Skip, Limit and Sort
The find operation takes a few extra, optional parameters which allow you to control
the number of documents that are returned from the query.
The limit option limits the result set to the desired size:
db['users'].find({active: true}, limit=10)
The skip option omits a number of documents from the start of the result set:
db['users'].find({active: true}, limit=10, skip=4)
The sort option allows you to specify how the result set should be sorted:
# sort by age ascending, then by name descending
db['users'].find({active: true},
limit=10, skip=4,
sort=[{'age': 1}, {'name': -1}]
)
Naturally, the skip, limit and sort options to find can be used in any
combination. If no sort order is specified, the result set is likely to be sorted
naturally in the order the documents were written to the collection. However, this
behaviour is not guaranteed, so if you care about ordering you should sort by a
document field which has meaning to your data.
Removing Data
Removing data from a collection can be accomplished with the remove, remove_one and remove_one_by_id operations. remove and remove_one take a query document and remove any documents which match the query, while remove_one_by_id takes a string id and removes the document in the collection with the same _id.
All of the remove* operations return an integer indicating the number of documents
that were removed.
Beware: the remove* operations will permanantly delete data. There is no way to recover data removed in this way.
Updating Data
At the moment, the only way to update a document in a collection is to use the save operation detailed above.